Ob in der Autowerkstatt, in Ihrem Fuhrpark oder im Versicherungsbüro: Täglich werden in Deutschland tausende von Fahrzeugscheinen erfasst und digitalisiert. Dieser Prozess ist aufwendig und birgt Fehlerpotenzial. Digitalisierung stellt an dieser Stelle eine Lösung dar. Allerdings ist die Erfassung eines Fahrzeugscheines mittels herkömmlicher Texterkennung eine Herausforderung. In diesem Blogbeitrag stellen wir am Beispiel der Fahrzeugscheinerkennung einen Ansatz vor, wie komplexe Texterkennungsaufgaben bei strukturierten Dokumenten mittels Künstlicher Intelligenz gelöst und bereitgestellt werden können.
Dreistufiger Erkennungsansatz für optimales Auslesen von Fahrzeugscheinen.
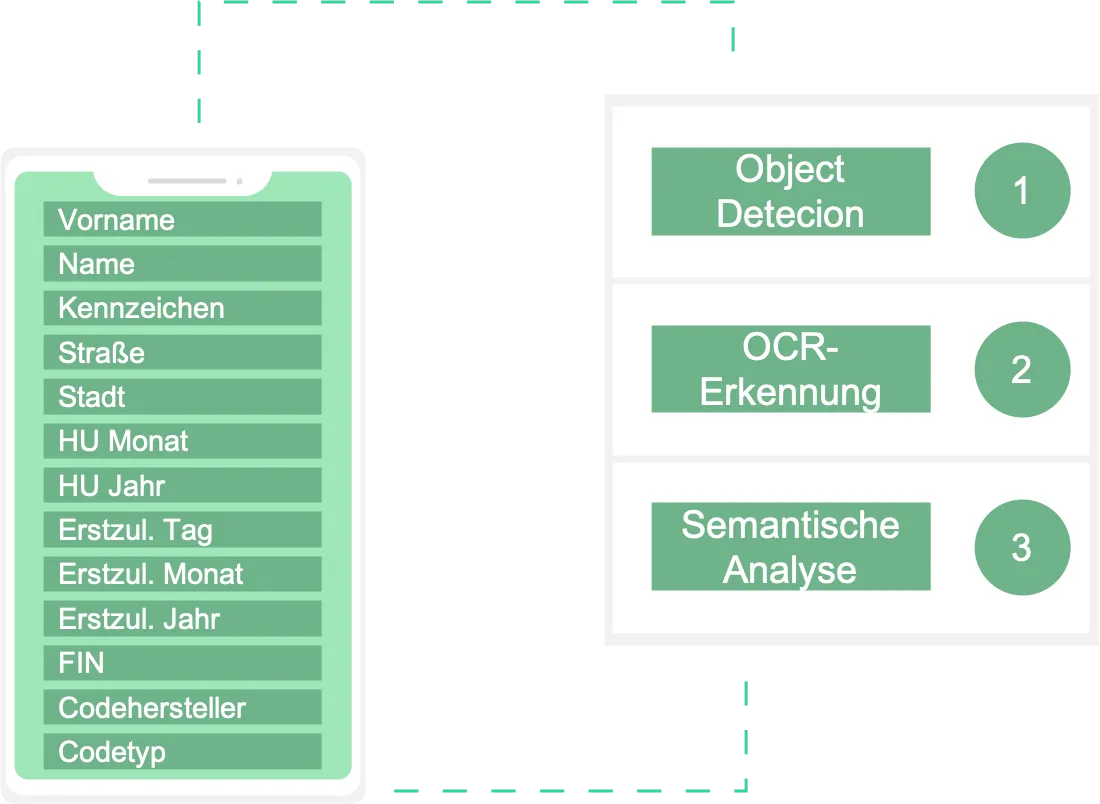
Der Mensch kann den Fahrzeugschein (wenn er diesen zuvor studiert hat oder dieser bekannt ist) einfach erfassen. Woran liegt das? Der Fahrzeugschein ist ein strukturiertes Dokument. Jede Angabe hat seinen festen Platz. Beispielsweise ist für das Kennzeichen ein Feld vorgegeben. Dieses befindet sich relativ gesehen immer an derselben Stelle auf dem Fahrzeugschein. Zudem weist ein Kennzeichen eine semantische Struktur auf. Diese Tatsachen haben wir uns bei der Entwicklung der Künstlichen Intelligenz zum Vorteil gemacht und einen mehrstufigen Erkennungs- und Analyseprozess implementiert.
-
Lokalisierung relevanter Positionen Mithilfe eines deep-learning Object Detection Modells werden relevante Positionen ermittelt. Object Detection ist eine Methode aus dem Gebiet Computer Vision. Mithilfe von Object Detection lassen sich Objekte auf Bildern lokalisieren und mittels eines Begrenzungsrahmen markieren. In unserem speziellen Fall sind die “Objekte” die auszulesenden Felder auf dem Fahrzeugschein. Das Modell ist dabei in einem Transferleaning Ansatz auf synthetisch erzeugten Bildern trainiert worden, die zuvor manuell gelabelt wurden. Labeln bedeutet, dass manuell ein Trainingsdatensatz erzeugt werden muss, auf dem die Positionen der Objekte markiert sind. Nach Abschluss des Trainingsprozesses wurde das Object Detection Modell auf einem unabhängigen Testdatensatz evaluiert. Die Lokalisierungsaufgabe konnte dabei vom Modell extrem gut gelernt werden. Auf real-world Bildern generalisiert das Modell bei Fahrzeugscheinen sehr gut (Accuracy der Lokalisierungsaufgabe von über 98,5 %). In der aktuellen Entwicklungsstufe können von unserer Künstlichen Intelligenz neun Felder vom Fahrzeugschein ausgelesen werden. Eine Erweiterung ist problemlos möglich.
-
Auslesen der relevanten Positionen Auf Basis der lokalisierten Positionen werden im zweiten Schritt die identifizierten Bildbereiche zugeschnitten und durch eine OCR-Erkennung digitalisiert. Dadurch entstehen zwei Vorteile: 1. Je auszulesendem Feld wird nur der Text ausgelesen, der auch zur entsprechenden Position gehört. 2. Aufgrund Lokalisierung muss nicht der gesamte Fahrzeugschein ausgelesen werden, sondern nur die zugeschnittenen Bereiche, wodurch eine effiziente Auslesung gewährleistet werden kann.
-
Semantische Analyse und Verifikation Die ausgelesenen Texte werden im dritten Schritt regelbasiert ausgewertet. Beispielsweise erfolgt beim Auslesen der Anschrift ein Abgleich mit einer Datenbank mit Postleitzahlen oder bei der Fahrzeugidentifizierungsnummer erfolgt ein Quercheck zum Feld des Herstellers. Durch die semantische Analyse und Verifikation wird sichergestellt, dass keine falschen Ergebnisse von der Künstlichen Intelligenz zurückgeliefert werden.
Jetzt Demo anfordern!
Bereitstellung mithilfe von FastAPI und Kubernetes.
Die Bereitstellung des Künstlichen Intelligenz Modells erfolgt über eine REST-Schnittstelle. Dafür verwendet dass mmmint.ai Team das Framework FastAPI. FastAPI bietet den Vorteil, dass eine automatisierte Dokumentation auf Basis von OpenAPI erstellt wird. Unsere Dokumentation der Fahrzeugschein Erkennung können sie unter der api.mmint.ai einsehen. Die FastAPI wurde von uns dabei über einen Container bereitgestellt. FastAPI bietet hierzu eine hervorragende Dokumentation zur Bereitstellung mit Docker.
Das Team hat dabei die twelve-factor app Methoden zur Entwicklung von Software-as-a-Service Applikationen beachtet und alle Konfigurationen z.B. über Umgebungsvariablen ausgelagert. Zur Skalierung der Applikation wenden wir dabei eine event-basierte Programmlogik an. Die aufwendige Analyse und Berechnung der Fahrzeugscheine erfolgt dabei im Hintergrund, während die Schnittstelle sofort wieder erreichbar ist. Um die Gewährleistung des Betriebes zu leisten und dabei eine hohe Verfügbarkeit bei geringen Kosten zu erzielen setzt das Team auf Kubernetes und Cloud-Anbieter.
Das mmmint.ai Team setzte von Beginn an auf eine gehostete Kubernetes Umgebung. Kubernetes ist ein Open-Source System für die automatisiere Bereitstellung, Skalierung und dem Management von containerisierten Applikationen. Da mmmint.ai mehrere auf Micro-Service Architektur basierte Applikationen anbietet, konnte die Registrationrecognition FastAPI somit einfach in die Server-Landschaft integriert werden.
Cloud Anbieter wie z.B. Microsoft Azure oder Amazon Web Services bieten mit AKS respektive EKS serverless Kubernetes Umgebungen an. Das mmmint.ai Team setzt dabei auf die spitzen Cloud-Anbieter um sich zukunftssicher im Cloud Umfeld aufzustellen. Wir wählen dabei bewusst die deutschen Rechenzentren für unsere Produktivumgebungen aus. Die Daten werden dabei in-transit als auch at-rest zu jeder Zeit verschlüsselt und sind ausschließlich durch einen sicheren APIKey von unseren Kunden abrufbar.
Die Entwicklung der Software-Lösung erfolgt dabei über unser Github Account mmmint-ai. Github Actions werden verwendet, um eine Reihe von Pythons statischen Analyse Tools (flake8, autopep8, pylint) sowie Unit-Tests auf Basis von pytest auszuführen. Das Team benutzt ein semantisches Versionierungsverfahren um Applikationen über Git-Tags zu versionieren. Pro commit in den main branch und GitTag wird ein neuer Container erstellt. Diese Container Versionen werden anschließend über einen GitOps Ansatz in dem Kubernetes automatisiert bereitgestellt. Mehrere Versionen können parallel zur Verfügung gestellt werden bzw. die Bereitstellungen erfolgen ohne Downtime voll automatisiert. Bei einer fehlerhaften Bereitstellung schlagen unsere Monitoring-Systeme Alarm und wir können innerhalb kurzer Zeit reagieren, sodass eine extrem hohe Verfügbarkeit der Schnittstelle gewährleistet werden kann.
Für mehr Informationen zu unserem MLOps sowie Cloud-Computing Angebot besucht unsere Workshop Serie.
More about mmmint.ai
Analog zur Auslese von Fahrzeugscheinen kann unsere Methodik auch zur digitalen Erfassen von anderen strukturierten Dokumenten verwendet werden, wenn extrem hohe Genauigkeiten gefordert sind. Sie müssen Dokumente strukturiert erfassen? Sprechen Sie uns gerne an. Sie sind Mitarbeiter einer Werkstatt, eines Fuhrparkunternehmens oder arbeiten gar direkt für eine Versicherung für PKW-Policen. Wir helfen Ihnen gerne Ihre Prozesse zu verschlanken!